
【儀表網 產業報道】水質在線監測通常依托部署于多個站點的傳感器,對pH、溶解氧、氮磷、高錳酸鹽指數、葉綠素等多種關鍵指標進行長期、高頻時序采集。然而,傳感器可能因設備故障、定期維護、校準或通信中斷等原因發生停測,造成數據序列出現大量空白;此外,還易受生物附著、極端天氣和人為干擾等因素影響,產生明顯偏離真實值的異常數據或隨機噪聲。這些問題嚴重制約了數據分析的準確性,對水質評價、污染溯源和預測預警等工作帶來極大挑戰。因此,開發高精度的數據修復技術顯得尤為重要。
水質數據天然具備“時間–空間–指標”三個維度,可在信息空間中表征為一個三維張量結構。傳統統計學插值方法難以有效利用這種多維關聯特性。而張量分解模型能夠將三維張量分解為一組低秩矩陣(核心因子)的乘積,分別提取出時間變化模式、空間分布模式和指標關聯模式,并藉此實現對缺失值的智能推斷。
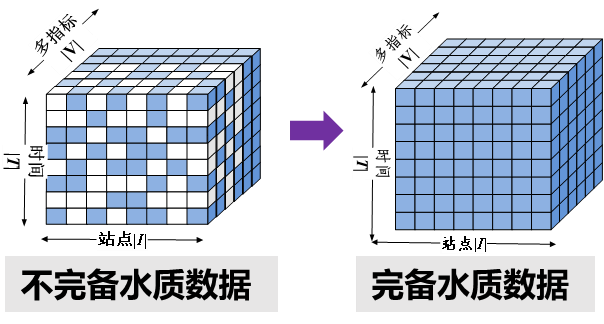
圖1:水質在線監測數據在信息空間中的三維張量表征
為更精準地刻畫不同水質數據時序特性,重慶研究院科研團隊創新性地將張量分解與偏差校正及智能優化算法相結合,提出了多偏差融合的自適應張量分解模型(DBAL)和多偏差非負張量分解集成模型(DBNE),并在云南高原湖泊滇池的水質在線監測系統上進行了應用與驗證。
自研模型在方法層面實現了多項突破:通過對指標施加非負約束,確保修復后的水質參數符合物理現實;融合單線性偏差、預處理偏差和時變感知偏差等多種機制,有效捕捉實際指標長期變化的季節性特征與短期波動規律等;引入差分進化算法,實現模型超參數的自適應優化,大幅提升調參效率。高原湖泊實驗結果表明,在隨機缺失(丟失率20%–80%)和連續缺失(丟失時長1–4周)等多種情景下,模型對多項水質指標的整體插補精度表現優異,Nash-Sutcliffe 效率系數(NSE)超過0.90,均方根誤差(RMSE)和平均絕對誤差(MAE)顯著優于現有主流模型。同時,模型具備高運行效率,全量數據處理耗時控制在5分鐘以內,滿足真實場景下模型應用部署需求。
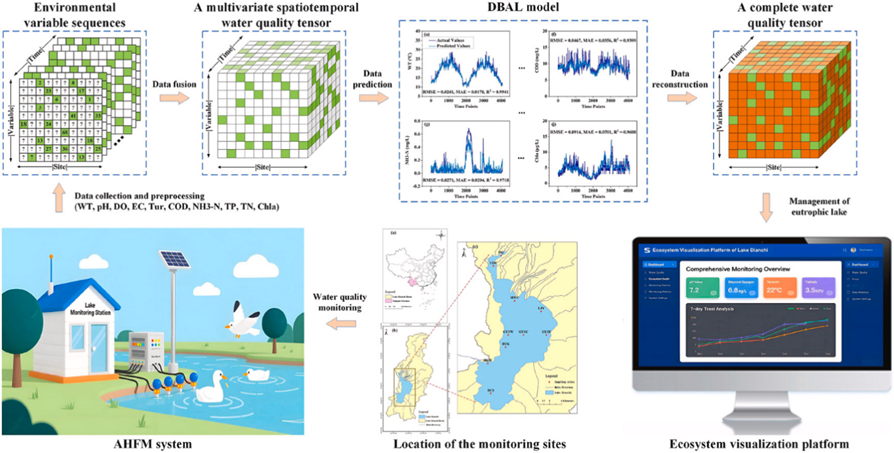
圖2:增強張量分解模型在云南高原湖泊滇池水質在線監測中應用
研究團隊提出的“張量分解-多偏差校正”框架具有較強的通用性與可遷移性,不僅能修復水質時序傳感數據,更可廣泛應用于水文水資源、大氣污染、土壤環境及生態質量評估等領域,有效重構多種復雜環境要素的缺失數據。
相關成果發表在《Environmental Modelling & Software》和《Ecological Informatics》等生態環境建模領域的主流期刊上。論文第一作者是重慶研究院與重慶郵電大學聯合培養博士研究生吳旭坷,通訊作者為閃錕研究員,相關研究獲得國家自然科學基金、云南省省市一體化重點專項、重慶市技術創新與應用發展重點專項等項目支持。




















所有評論僅代表網友意見,與本站立場無關。